Overview
Join Monster fetches only the data you need - nothing more, nothing less, just like the original philosophy of GraphQL.
It reads the parsed GraphQL query, looks at your schema definition, and automatically generates the SQL that will fetch no more than what is required to fulfill the request.
All data fetching for all resources can be done in one or a few queries using the power of JOINs.
Modeling Your Data
There are a few constraints in order for SQL's relational model to make sense with GraphQL's hierarchical one.
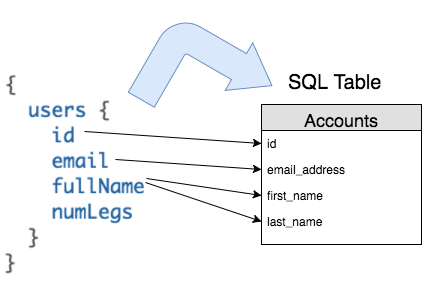
SQL tables must be mapped to a GraphQLObjectType.
Fields on this GraphQLObjectType can depend on one or several SQL columns (e.g. a fullName field may need a last_name and a first_name column in the table).
Not all fields have to have a corresponding SQL column(s).
They can be derived from arbitrary SQL expressions.
Some can resolve data from other sources entirely.
Each instance of the object type is one row from it's mapped table. Fields which are a GraphQLList of your table's object type represent any number of rows from that table. If you schema includes any such lists, your table must also have a unique key.
If one table's object type is nested as a field within another table's object type in the GraphQL schema, the data can be fetched as a JOIN or in one separate query.
Adding Metadata
So Join Monster needs some additional metadata in order to write the right SQL. How does one declare these mappings, and unique keys, and joins, etc.?
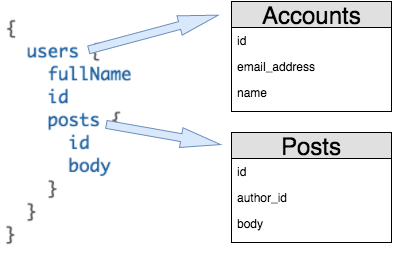
These are declared by decorating the schema definition with some additional properties that Join Monster will look for. Below is an example of mapping the User object to an accounts table that joins on posts for a Post object. For details see the following Usage section.
const User = new GraphQLObjectType({
name: 'User',
sqlTable: 'accounts',
uniqueKey: 'id',
fields: () => ({
id: {
type: GraphQLInt,
extensions: {
joinMonster: {
sqlColumn: 'id'
}
}
},
email: {
type: GraphQLString,
extensions: {
joinMonster: {
sqlColumn: 'email_address'
}
}
},
immortal: {
type: graphQLBoolean,
resolve: () => false
},
posts: {
type: new GraphQLList(Post),
extensions: {
joinMonster: {
sqlJoin: (userTable, postTable) =>
`${userTable}.id = ${postTable}.author_id`
}
}
}
})
})
Join Monster provides a declarative API that lets you define data requirements on your object types and fields. By placing these properties directly on the schema definition, GraphQL effectively becomes your ORM because it is the mapping between the application and the data.
Notice that most of these fields do not have resolvers. Most of the time, adding the SQL decorations will be enough. Join Monster fetches the data and converts it to the correct object tree structure with the expected property names so the child resolvers know where to find the data.
Also notice the immortal field, which does have a resolver. This field demonstrates how not all the fields must come from the batch request. You can write custom resolvers like you normally would that gets data from anywhere else. Join Monster is just a way of fetching data, it will not hinder your ability to write your resolvers. You can also have your fields get data fron a column and apply a resolver to modify, format, or extend the data.
Calling the Function
Once you map a GraphQLObjectType to a SQL table, any field with that type, along with all of its descendants, can be fetched by calling joinMonster from the resolve function. All you have to do is pass it the resolveInfo, the 4th parameter of the resolve function. You then write a callback to receive the generated SQL, call your database, and return the raw data. Join Monster will take it from there and return the shaped data.
We assigned the User type to the accounts table, so we can do the following on any field of type User, new GraphQLList(User), or new GraphQLNonNull(User).
users: {
type: new GraphQLList(User),
resolve: (parent, args, context, resolveInfo) => {
return joinMonster(resolveInfo, {}, sql => {
// knex is a SQL query library for NodeJS. This method returns a `Promise` of the data
return knex.raw(sql)
})
}
}